在stanford coreNLP的网页中直接以树的形式可视化了解析结果。但在IDE中,利用python调用coreNLP server后返回的是字符串格式。这是可以利用nltk中的Tree类来可视化解析结果。代码如下:
from nltk.tree import Tree
from stanfordcorenlp import StanfordCoreNLP
sentence = '我叫小米'
with StanfordCoreNLP(r'E:\ProgramData\Anaconda3\coreNLP\stanford-corenlp-full-2016-10-31', lang='zh') as nlp:
Tree.fromstring(nlp.parse(sentence)).draw()
这里是通过stanfordcorenlp库来使用coreNLP的。
直接返回的结果是:
(ROOT
(IP
(NP (PN 我))
(VP (VV 叫)
(NP (NN 小米)))))
可视化: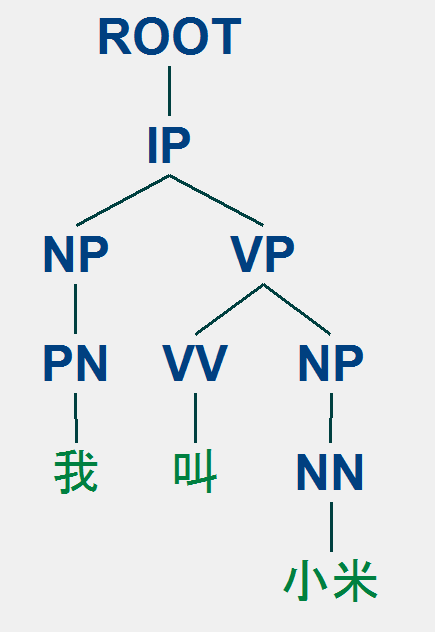
关于环境部署可见:两种在Python中使用Stanford CoreNLP的方法
当然这里也可以使用Stanford parser 来构建中文语法树,可视化方法类似。链接见:NLTK中使用Stanford parser 构建中文语法树


![Keras examples-imdb_cnn[利用卷积神经网络对文本进行分类]](https://raw.githubusercontent.com/xiongzongyang/hexo_photo/master/keras04.png)
